论文链接:https://arxiv.org/pdf/1901.00212v3.pdf
文章简介
19年1月新鲜出炉的image inpainting任务上的state-of-the-art(关键是还开源!!).现阶段一般的方法,不能重构出特别合理的结构,大部分是比较模糊。Edgeconnect是一个two-stage的对抗模型,第一阶段image-to-edge后的一个边生成器,将图像缺失区域的边生成,第二阶段edge-to-image图像补全网络,以边为先验补全图像。
相关工作
18年深度学习处理图像修复问题有很大进展
- 1月,Adobe组,Jiahui Yu的Deepfill v1,引入attention机制用于进行image inpainting,但是限制是mask仅限于中心正方形作为遮挡,对于测试效果还是有明显的boundary artifacts,看到很明显的生成部分与原来图像部分的分界,这方面主要原因是合成图片结果就是将缺失部分用预测结果,未缺失部分继续用原图然后直接合成。
- 4月,NVIDIA组,提出的partial-conv,可以修复irregular holes。
- 6月,Yan et al, 提出shift-net,引入shift connection layer到U-net.
- 6月,Adobe组,Jiahui Yu的Deepfill v2,提出了门控卷积(gated-conv)解决普通卷积里把所有输入像素都视为合法输入的问题,泛化了部分卷积(partial-conv)。对于所有layers中的每个channel每个空间位置提供一种可学习的动态特征选择机制。优势是可以通过素描画笔来引导inpainting,而且适用于irregular holes.
一些思考
- 1.对比EdgeConnect与DeepFill v2(Free form image inpainting with gated convolution),从训练数据分布上来说:
- DeepFill v2: 由于Deepfill v2作为input的edge channel可能是ground-truth通过边缘检测生成的,与图片一起作为ground truth的一部分来监督。但是,测试阶段的时候,边缘是人为绘制的,虽然有很好的自由性,但从数据分布的角度上看,可能人为绘制出的边缘与ground truth的边缘有些差别,所以可能导致inpainting效果没有特别好。
- EdgeConnect: 训练的时候用于edge-connect的边缘监督ground truth,是通过图片边缘检测得到的,然后根据幻想的边缘结果来作为先验生成补全图像,整个测试过程与训练过程从数据分布上讲是一致的,理论上如果边缘连接效果好的话,EdgeConnect的效果是要优于DeepFill v2的,但也牺牲了一些自由性。
- 2.EdgeConnect的理念是“Lines first, color next!”, 根据之前人类如何sketch物体的论文思想总结出image inpainting里面边缘其实对画画的影响比颜色大的多。但是思考点是对于深度学习里数据分布上,rgb的数据,color next这样弱化颜色对数据影响真的好吗?
算法过程
作者认为相较于图像补全,边的恢复是一个更简单的任务。所以作者提出的方法在本质上是分解成缺失区域高频信息和低频信息的补全。
边生成器
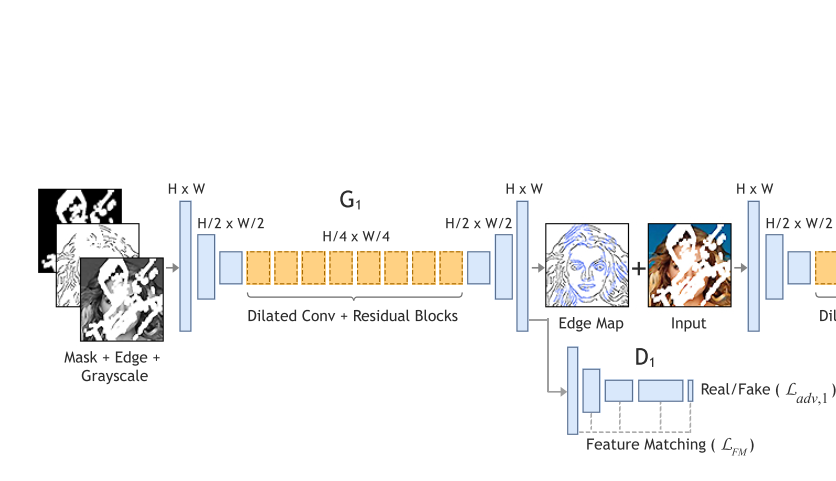
定义:$I_{gt}$ 表示ground-truth图像, $C_{gt}$ 表示边图ground-truth, $I_{gray}$ 表示ground-truth的灰度图
使用掩码后的灰度图(masked grayscale image) $\tilde{I_{gray}}=I_{gray}\odot(1-M)$ 作为输入
$\tilde{I_{gray}}$ 的边图: $\tilde{c_{gt}}=C_{gt}\odot(1-M)$ 作为输入
边生成器网络输出(edge connect的结果): $C_{pred}=G_{1}(\tilde{I_{gray}},\tilde{C_{gt}},M)$
(其中 $M$ 表示掩码)
其中 $G_1$ 就是边生成器,$G_1$的损失函数就是:
其中 $\lambda_{adv,1}$ 与 $\lambda_{FM}$ 就是正则化项
对抗损失就是:
(Discrimator1尽量最大化这个损失,Generator1则希望最小化)
Discriminator的输入是边图 $C$ , 灰度图 $I_{gray}$
$L_{FM}$损失就是:
$N_i$ is the number of elements in the i’th activation layer, $D_1^{(i)}$ is the activation in the i’th layer of the discriminator
这符合HED边缘检测的思路,HED边缘特征就是根据CNN每层激活层特征总和提取的。
训练策略:WGAN+SN(spectual normalization,谱归一化),其中设置 $\lambda_{adv,1}=1$ 与 $\lambda_{FM}=10$
图像补全网络
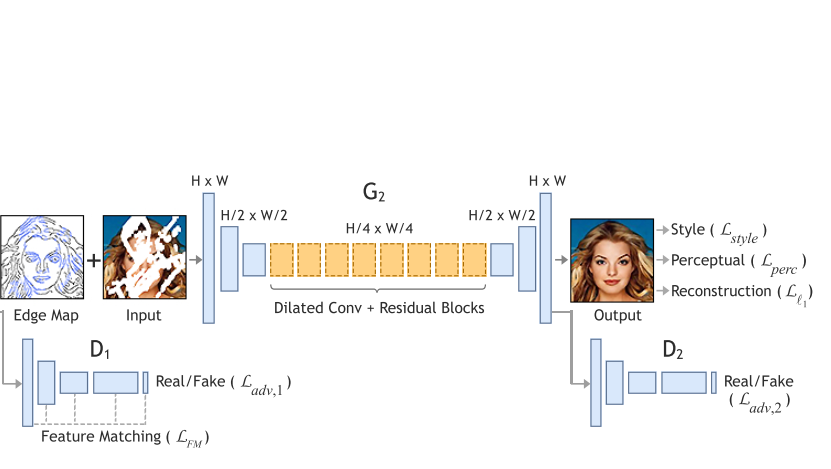
不完整的彩色图像 $\tilde{I_{gt}}=I_{gt}\odot(1-M)$ 作为输入
经过上一阶段后合成的边图 $C_{comp}=C_{gt}\odot(1-M)+C_{pred}\odot M$ 作为输入
图像补全网络得到的结果:$I_{pred}=G_{2}(\tilde{I_{gt}},C_{comp})$
总损失函数:
$L_{adv,2}$ 对抗损失:
$L_{perc}$ perceptual loss:
$L_{perc}$ penalizes results that are not perceptually similar to labels by defining a distance measure between activation maps of a pre-trained network.
$\phi_i$ is the activation map of the i’th layer of a pre-trained network. For our work, $\phi_i$ corresponds to activation maps from layers relu1-1, relu2-1, relu3-1, relu4-1 and relu5-1 of the VGG-19 network pre-trained on the ImageNet dataset.
$\phi_i$ 就表示某层的activation map
$L_{style}$ style loss:
$G_j^{\phi}$ is a $C_j$ × $C_j$ Gram matrix constructed from activation maps $\phi_j$.
We choose $\lambda_{l_1} = 1$ , $\lambda_{adv,2} = \lambda_{p} = 0.1$ , and $\lambda_s = 250$
对于图像复原网络,使用谱归一化会极大地增加耗时,所以不使用谱归一化。
实验过程
生成training labels (edge maps)使用Canny edge detector, Gaussian smooth filter $\sigma = 2$
网络训练使用256×256的图像,batchSize=8
优化方法Adam optimizer,$\beta_1=0, \beta_2=0.9$
学习率开始是 $10^{-4}$ 之后进入losses plateau后学习率调整为 $10^{-5}$ ,训练 $G_1$, $G_2$ 直到收敛
最终的时候:再移除 $D_1$ 进行fine-tune,然后训练 $G_1$, $G_2$,使用学习率为 $10^{-6}$直到收敛,其中discriminator的学习率都是generator的1/10
网络结构
Generator的结构
网络结构采用的是斯坦福 johnson et al. 提出的perceptual loss文章里的结构,因为这篇文章的generator也采用了perceptual loss相关的损失函数,所以也采用这个网络结构作为网络模型。
注释:
- ck: a 7 × 7 Convolution-SpectralNorm-InstanceNorm-ReLU layer with k filters and stride 1 with reflection padding
- dk: a 4 × 4 Convolution-SpectralNorm-InstanceNorm-ReLU layer with k filters and stride 2 for down-sampling
- uk: be defined in the same manner as dk with transpose convolution for up-sampling
- Rk: a residual block of channel size k across both layers (在Rk的第一层使用dilation convolution,dilation factor = 2,之后跟随spectral normlization + instance normalization
- c: In the edge generator $G_1$ , c has channel size of 1 with sigmoid activation for edge prediction. In the image completion network $G_2$, c* has channel size of 3 with tanh (scaled) activation for the prediction of RGB pixel intensities.
- In addition, we remove spectral normalization from all layers of G2.
Discriminator的结构
网络采用的是70 × 70 PatchGAN (Image-to-image translation with conditional adversarial networks, CVPR2017)里面的网络结构.
注释:
- Ck-s: a 4 × 4 Convolution-SpectralNorm-LeakyReLU layer with k filters of stride s
- The final convolution layer produces scores predicting whether 70 × 70 overlapping image patches are real or fake
- LeakyReLU is employed with slope 0.2.
未来工作
- Plan to investigate better edge detectors, 因为目前对于复杂数以百计的边缘区域生成效果很差。
- 全卷积生成网络使用,应该会有更好的生成效果对于修复高分辨率图像。
(个人想法:)
- 基于Contextual Attention,网络引入根据周围像素来判断生成的单元机制
- 整个生成模型是个二阶段的模型,中间结果是边缘,边缘属于让人理解的一种representation,能不能找到一种让机器理解的中间阶段representation,从而有更好的修复效果。