论文链接:http://iizuka.cs.tsukuba.ac.jp/projects/completion/data/completion_sig2017.pdf
文章简介
siggraph2017, 本文提出的图像补全算法,可以保持图像在全局与局部都一致。mask可以是任意形状。
网络结构
主要是用GAN的思路,总共有生成器与鉴别器两个部分三个网络。
生成部分:生成网络
鉴别部分:全局鉴别器+局部鉴别器
网络中激活层:Relu,最后一层采用sigmoid函数,使输出范围在0-1之间
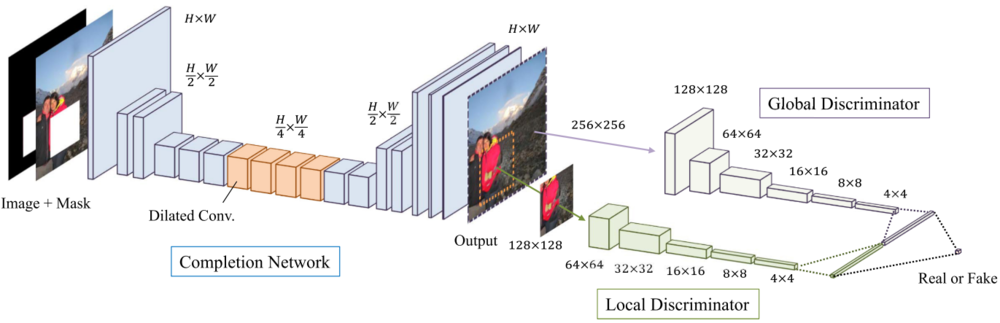
输入是RGB图像+mask,输出是RGB图像
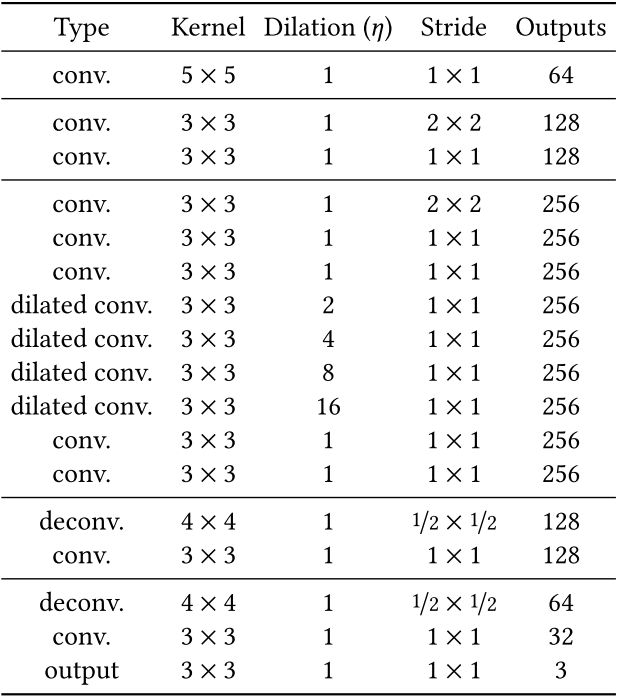
生成网络:作者采用12层卷积网络对预处理的原始图片进行encoding,下采样两次,得到一张原图大小1/4 x 1/4大小的网格。然后再对该网格采用4层卷积网络进行decoding,从而得到复原图像。
鉴别网络:一个全局鉴别器(Global Discriminator)以及一个局部鉴别器(Local Discriminator)。全局鉴别器将完整图像作为输入,识别场景的全局一致性,而局部鉴别器仅在以填充区域为中心的原图像4分之一大小区域上观测,识别局部一致性。通过采用两个不同的鉴别器,使得最终网络不但可以使全局观测一致,并且能够优化其细节,最终产生更好的图片填充效果.
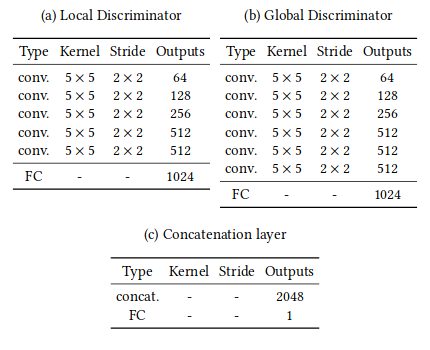
全局鉴别网络输入是256x256,RGB三通道图片,局部网络输入是128x128,RGB三通道图片,根据论文当中的设置,全局网络和局部网络都会通过5x5的convolution layer,以及2x2的stride降低分辨率,最终分别得到1024维向量。然后,作者将全局和局部两个鉴别器输出连接成一个2048维向量,通过一个全连接然后用sigmoid函数得到整体图像一致性打分
损失函数
两个loss联合使用:
- a weighted Mean SquaredError (MSE) loss for training stability
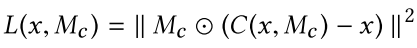
- a Generative AdversarialNetwork (GAN) loss to improve the realismof the results
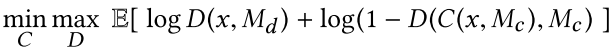
合成后的总loss:
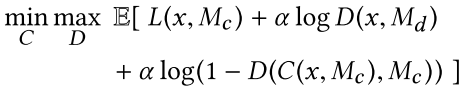
(其中 $\alpha=0.0004$ , $M_c$ 表示mask, $x$ 表示input image, $C$ 表示Completion network, $D$ 表示discriminator,显然D也需要mask作为输入从而确定局部中心)
训练参数及技巧
训练图片:8,097,967 training images taken from the Places2 dataset
Batch size: 96 images
learning rate: ADADELTA algorithm (Zeiler 2012),which sets a learning rate for each weight in the network automati-cally
The completion network is trained for $T_C = 90000$ iterations
The discriminator is trained for $T_D = 10000$ iterations
Finally both are jointly trained to reach $T_{train} = 500000$ iterations
The entire training procedure takes roughly 2 months on a single machine equipped with four K80 GPUs
Tricks
- 训练数据预处理为256x256:将图像的较短边resize成(256,384)中的一个随机数(等比例resize)从图像上随机crop一个256x256的图片。
- 输入图片预处理,在completion region上overwrite一个constant color.
一些想法
1. 关于生成网络,仅仅降采样了两次
使用大小为原始大小四分之一的卷积,其目的是为了降低最终图像的纹理模糊程度。
2. 使用空洞卷积
它能够通过相同数量的参数和计算能力感知每个像素周围更大的区域。Multi-Scale Context Aggregation by Dilated Convolutions
为了能够计算填充图像每一个像素的颜色,该像素需要知道周围图像的内容,采用空洞卷积能够帮助每一个点有效 的“看到”比使用标准卷积更大的输入图像区域,从而填充图中点的颜色
空洞卷积的感受野计算得到,该网络:
- dilated convolutions:307×307 pixels
- standard convolutional:99×99 pixels
对于 307x307 pixels,显然在训练中256x256数据没有什么问题,但是测试的时候图片较大就存在问题了,可能1600x1200的图像就看不到离该像素点很远的区域了
3. 对于这个网络结构基本后来很多论文都采用类似的结构,降采样2次+空洞卷积
例如:19年1月的edge-connect:只是把普通层堆叠升级成了residual block
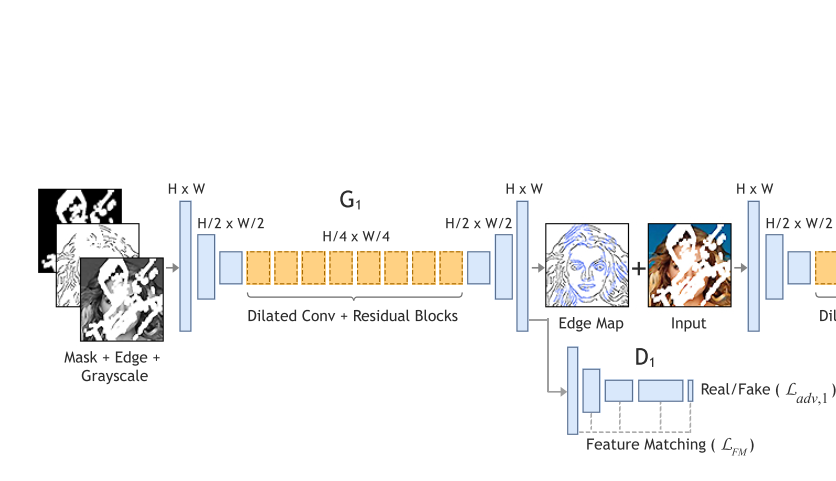
之后相关领域有改进增加了gated convolution, GAN也改进为WGAN+SN